Das Verständnis von Langtexten und Dokumenten ist eine Aufgabe, die Menschen sehr viel Zeit kostet, aber leicht von Maschinen erledigt werden kann. Mittlerweile gibt es Systeme mit Künstlicher Intelligenz, welche diese Aufgabe mit passendem Training effizient und exakt passend auf verschiedene Anwendungsfälle erledigen können. Dazu benötigt es nicht einmal Tiefenwissen über Funktionsweise und zugrundeliegende Algorithmik der Systeme - IBMs Watson Discovery liefert diese Vorteile und Nutzungsmöglichkeiten out-of-the-box.
IBMs KI-Lösungen liefern seit Jahren viel Stoff für Berichterstattung, ob nun Schachcomputer DeepBlue oder Jeopardy-KI Watson, die beide ihre menschlichen Gegner schlugen. Dementsprechend wurde der 2017er Rollout von Watson Discovery als mächtigem Werkzeug für kognitive Textanalyse erwartet. Zwei Jahre später und um einige Features reicher ist die Liste von Anwendungsfällen, die mit Watson Discovery realisiert werden können, nur gewachsen. Doch was kann Watson Discovery und worin bestehen die Herausforderungen, die IBM mit diesem Dienst angeht?
Textverständnis und Cognitive Analysis
Unter Textverständnis versteht man im Kontext von KI die Aufnahme von größeren Textkorpora mit Segmentierung und Klassifikation der Inhaltselemente unter Betrachtung des Vorkommenskontextes. Im Anschluss der Analyse ist häufig ein Abfragemechanismus eingearbeitet, der unter Nutzung der Klassifikationen eine effizientere Suche nach Inhalten ermöglicht. Erweitert man das Textverständnis um das Herausziehen von Anliegen oder überspannenden Konzepten (bspw. dem Konzept von Therapie oder Anamnese in einem medizinischen Bericht), so bewegt man sich im Bereich der Cognitive Analysis – verglichen mit der einfachen Textanalyse also das Verständnis des „Big Picture“.
Eine Herausforderung bei der Analyse von Langtexten besteht hier im unstrukturierten Vorliegen der Daten – ein Vertrag mag mit Textabschnitten und einem Briefkopf für Menschen intuitiv verständlich sein, für einen Computer sind diese aber in Rohform nicht direkt verarbeitbar, er muss zunächst auf diese Form des Inhalts trainiert werden. Hier unterstützt der Mensch beim Training der Inhalts-Segmentierung. Die Discovery-KI lernt, wie sie Dokumente aufteilen kann und wendet diese Segmentierung später selbst an.
Eine weitere Herausforderung zeigt sich bei den Abfragemechanismen, denn die wenigsten potentiellen Nutzer möchten spezielle Abfragesprachen wie SQL erlernen. IBM legt hier mit der Möglichkeit, Abfragen in natürlicher Sprache zu formulieren, eine Lösung vor, welche diese Lernhürde nimmt. Gleichzeitig ermöglicht dies, z.B. Chatbots mit Watson Discovery zu erweitern, welche die Nutzereingaben direkt weitergeben und einen Dokumentenkorpus oder eine Website nach der passenden Antwortpassage durchsuchen. Hierzu bietet Watson Assistant direkt die Einbindung einer Suchfertigkeit an.
Aufnehmen – Anreichern - Abfragen
Grundsätzlich läuft KI-gestützte Suche mehrschrittig ab, wie auch im Fall von Watson Discovery.
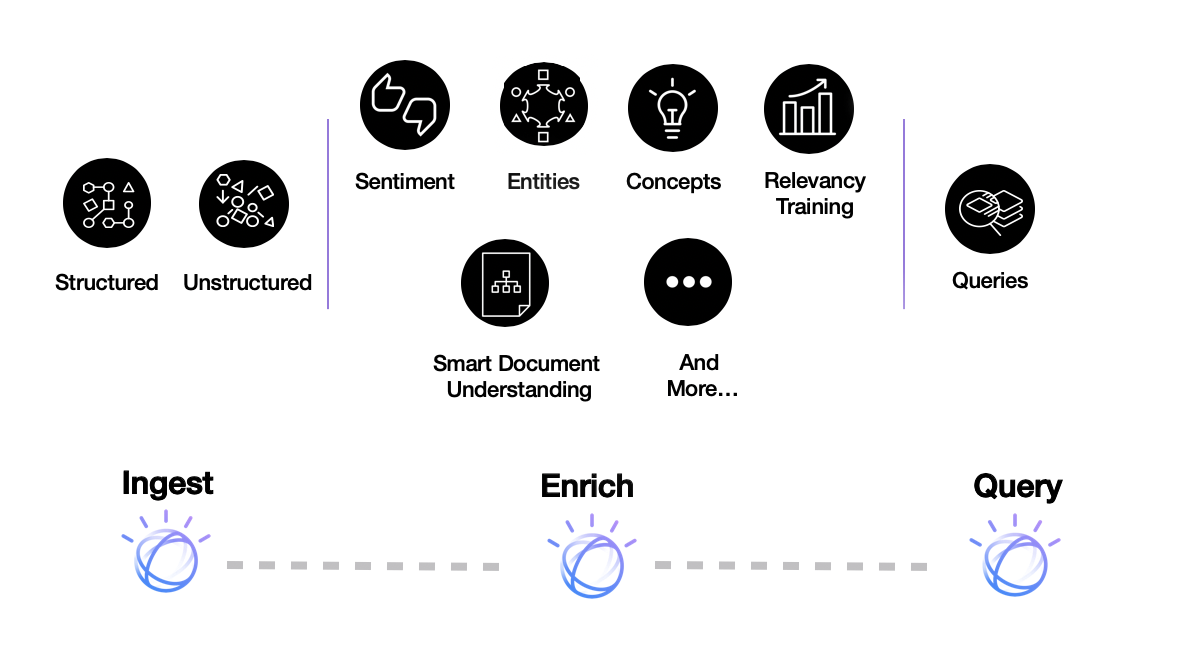
Schritt 1: Aufnehmen
Im ersten Schritt werden die Daten eingelesen und in einigen Fällen von einem Menschen so markiert, dass Inhaltselemente klassifiziert sind, in einem Brief z.B. als Anrede, Adresse, Kontodaten-Block etc. So wird aus einer unstrukturierten Datenmenge recht fix eine für den Computer lesbarere, strukturiertere Form. Ob die Daten nun aus einer Website, vielen PDF-Anleitungen oder eingescannten Dokumenten stammen, ist Discovery erstmal egal. Auch ist es mit der Annotationsanwendung Watson Knowledge Studio möglich, per Klick sehr genaue Sprachmodelle mit Zuordnungen zu vorkommenden Entitäten zu erstellen, welche die Ergebnisse deutlich verbessern können. So kann es Discovery auch schaffen, sich spezifisch auf Fachdomänen einzustellen, beispielsweise medizinische Daten, Verträge oder technische Anleitungen.
Schritt 2: Anreichern
Im zweiten Schritt werden die Daten angereichert, nach dem Training werden Segmente und Inhalte der Dokumente mit Klassifikationen versehen, die z.B. folgende Fragen beantworten können:
- Was sind die übergeordneten Konzepte, die in diesem Text vorkommen?
- Welche Formen von Entitäten werden erkannt (Personen, Orte, Tätigkeiten etc.) und welche Relationen haben diese zueinander?
- Mit welchem Grundgefühl (positiv/neutral/negativ) werden diese Inhalte belegt?
- Aus welchen Feldern (Überschriften, Kopfzeilen, Adressblöcken, Textblöcken etc.) besteht ein Dokument?
- Welche Schlüsselworte kommen wie häufig im Dokumentenkorpus vor?
Schritt 3: Abfragen
Im letzten Schritt der Abfrage werden in natürlicher Sprache oder über die hauseigene Abfragesprache z.B. Vorkommen von bestimmten Entitäten oder Gefühlslagen im Dokumentenkorpus ausgeführt. Hier kommt IBM zugute, dass man mit Discovery auch problemlos auf Deutsch interagieren kann.
Vielseitige Anwendungsfälle für KI-gestütztes Textverständnis
Im Bereich Kundenservice vereinfacht Dokumentenanalyse die Bereitstellung von Informationen. Stellen wir uns ein Montagehilfsprogramm vor: Dieses kann durch das automatische Durchsuchen von Bedienungsanleitungen die menschlichen Monteure zeitsparend unterstützen. Hierbei ist vor allem wichtig, dass ein Endnutzer eine Frage ja nicht nur auf eine Art formulieren kann. In natürlicher Sprache gibt es meist mehr als eine Formulierung für eine Absicht. Dies kann durch die KI-gestützte Analyse umgangen werden, denn alle Nutzereingaben werden auf die Basisabsicht heruntergebrochen. So ist es egal, ob nun in den Anleitungen für einen PKW wie in der von IBM bereitgestellten Demo nach „Wie stelle ich eine Kindersicherung ein?“ oder „Wie installiere ich Sicherheitsgurte am Kindersitz?“ gefragt wird. Die KI-Suchmaschine wird nach der Essenz der Frage fahnden, nicht nach der exakten Formulierung.
Auch im Bereich automatischer Dokumentenverarbeitung kann Discovery unterstützen. Mit Hilfe der Inhaltssegmentierung ("Smart Document Understanding") und Anreicherung wird es möglich, Dokumente automatisch zu klassifizieren, zu vergleichen oder in ihre Einzelteile zu zerlegen.

Chatbots sind im inhaltlichen Training zeitintensiv, jedoch es ist möglich, ihnen eine Textverständnis-KI an die Hand zu geben, um ihren Wissensschatz zu vergrößern. Das Durchsuchen von Websites oder Dokumenten nach Informationen, die ihnen noch nicht beigebracht wurden, erweitert ihre Antwortmöglichkeiten und damit den Kundennutzen. Besonders erwähnenswert ist hierbei, dass Watson Discovery die Texteingaben der Chatbot-Nutzer direkt abgreifen kann, denn der Abfragetyp „Natürliche Sprache“ ist genau hierfür geeignet. Auch lässt sich z.B. ein Watson Assistant (IBMs Chatbot-System) problemlos um eine Discovery-basierte Suchfähigkeit erweitern, ohne eine Zeile Code schreiben zu müssen.
Nun leben KI-Lösungen ja davon, dass sie mit mehr Daten besser werden – hier kann die Nutzerrückmeldung eine ganz entscheidende Rolle spielen. Wird beispielsweise eine von Discovery generierte Nachricht im Chatbot mit „hilfreich“ oder „nicht hilfreich“ markiert, kann diese Rückmeldung in das System eingespeist werden. So werden Schwachstellen und Uneindeutigkeiten identifiziert und das Training kann verfeinert werden.
Warum KI bei Textverständnis
Ein großer Vorteil der Nutzung von Künstlicher Intelligenz für die Aufgabe des Textverständnisses ist die Schnelligkeit. Während ein Mensch für das Auffinden bestimmter Informationen in einer 150-seitigen PDF problemlos eine Stunde aufbringen muss, kann eine auf diesen Texttyp trainierte KI dies in wenigen Sekunden erledigen.
KI-gestütztes Textverständnis schafft bei einer Vielzahl von Anwendungsfällen einen Mehrwert durch Zeitersparnis, Vielseitigkeit und beste Anpassbarkeit an Anwendungsfälle. Generell geht es hierbei aber nicht darum, menschliche Intelligenz komplett zu ersetzen – so weit sind die als „schmale Künstliche Intelligenz“ bezeichneten Systeme längst nicht. Dennoch können sie zeitintensive Prozesse für uns Menschen verkürzen, unseren Fertigkeitenkatalog also erweitern und uns bei der Verarbeitung von Daten mehr Zeit für die Bereiche lassen, in denen menschliche Intuition und Kontexterfassung noch zu kompliziert für eine KI sind. Gerade in Kombination mit Watson Assistant für Chatbots und Watson Knowledge Studio zum Training bietet Watson Discovery sehr feine Einstellmöglichkeiten, um diesen Fertigkeitenkatalog abbilden zu können.
Im nächsten Beitrag erfahren Sie, wie eine konkrete technische Umsetzung mit Watson Discovery aussehen kann.
Haben Sie große Mengen von Dokumenten zu verarbeiten?
Wenn Sie eine Entlastung durch eine KI-basierte Dokumentenverarbeitung gebrauchen können, dann sind wir von assono der richtige Ansprechpartner. Gerne informieren wir Sie in einem kostenlosen Beratungsgespräch über unsere Angebote. Kontaktieren Sie uns dafür gerne unter +49 4307 900 408 oder vereinbaren Sie hier einen Termin.





